Table of Contents
- Introduction
- Definitions
- Discussion
- Solutions and Actions
- Conclusions and Next Steps
- Case Studies
- Additional Resources
- References
Introduction
Over the past century, maintenance has evolved from a nuisance cost of doing business to an economic, strategic, and resilience engagement. Whereas maintenance was once a subfunction within an organization designed to handle equipment failure, it has now been transformed into an essential departmental principle.
As buildings, systems, and equipment become more technologically complex, so too have their maintenance approaches, processes, and procedures. What started over 100 years ago as a method of failure response and correction has now transformed into failure analysis; simple preventive activities have given way to predictive functions, and the nuisance cost of doing business has changed into a reliability-based strategic program within many agencies and industries.
Well-practiced operations and maintenance (O&M) is one of the most cost-effective methods for assuring reliability, safety, resilience, and energy efficiency. Good maintenance practices can generate substantial energy and cost savings and should be considered as a resource. Moreover, improvements to facility maintenance programs can often be accomplished immediately and at a relatively low cost.
While there are many definitions of O&M, the following is particularly comprehensive (FEMP 2010):
Operations and Maintenance are the decisions and actions regarding the control and upkeep of property and equipment. These are inclusive, but not limited to the following: 1) actions focused on scheduling, procedures, and work/systems control and optimization; and 2) performance of routine, preventive, predictive, scheduled and unscheduled actions aimed at preventing equipment failure or decline with the goal of increasing efficiency, reliability, resilience, and safety.
Modern and effective O&M programs rely on four basic approaches: (1) reactive/corrective maintenance—fix/replace when broken; (2) preventive maintenance—time-based actions; (3) predictive maintenance—fix it before it breaks; and (4) reliability-centered maintenance (RCM)—a strategic combination of the previous three approaches coupled with root cause analytics. This Best Practice will focus on the fourth approach and highlight the benefits of RCM for optimizing O&M program design and delivery. This Best Practice presents the process and development path, elements of a successful RCM program, and cost effectiveness via two case studies.
Definitions
- Asset. A maintenance term commonly taken to mean any item of the physical plant or equipment.
- Backlog. Work that has not been completed by the nominated required-by date. The period for which each work order is overdue is defined as the difference between the current date and the required-by date.
- Benchmarking. The process of comparing performance with other metrics or organizations.
- Downtime. The time that an item of equipment is out of service as a result of equipment failure.
- Failure. When an item of equipment can no longer perform one or more of its intended functions, it has failed.
- Failure Mode Effects Analysis (FMEA). A structured approach to identifying and characterizing potential failures in a design or application and assessing, as well as assessing their relative impact.
- Key Performance Indicators (KPIs). A select number of key measures, calculations, or metrics that allow performance tracking against target values.
- Motor Analysis. A predictive maintenance technology focused on faults that are within and intrinsic to electric motors and that result from winding short circuits, open coils, or improper torque settings.
- Oil Analysis. A predictive maintenance technology focused on the lubrication system and the fluid and wear elements within the lubrication medium (i.e., oil).
- Performance Trending. A maintenance activity centered on capturing, tending, and tracking key indicators of a component or system.
- Reliability. The ability of an asset to continue performing its intended functions. Normally, the mean time between failures is used as a metric.
- Repair. Any activity that returns the capability of an asset that has failed to a level of performance equal to or greater than what is specified by its functions but that is not greater than its original maximum capability. An activity that increases the maximum capability of an asset is a modification.
- Risk. The potential for the unwanted, negative consequences of an event to be realized.
- Root-Cause Analysis. A structured approach to identifying and characterizing failures and identifying the processes and actions needed to prevent them.
- Thermography. A predictive maintenance technology focused on generating visual infrared images that are useful in assessing heat-related stressors in a component or system.
- Unscheduled Maintenance. Any maintenance work that has not been included on an approved maintenance schedule before its commencement.
- Ultrasonic Analysis. A predictive maintenance technology that focuses on the sound waves emitted at frequencies above 20 kilohertz and the changes that can indicate equipment performance, degradation, or both.
- Useful Life. The maximum length of time that a component can be left in service before it will start to experience a rapidly increasing probability of failure.
- Vibration Analysis. A predictive maintenance technology focused on the periodic motion and cyclic patterns intrinsic to rotating machinery and equipment. These analytics are used to assess how changes in those patterns can be indicative of equipment performance and/or degradation.
Discussion
The previous Best Practice, “Maintenance Approaches,” provides the groundwork for the optimization of maintenance by offering traditional definitions of the three basic types of maintenance approaches (reactive, preventive, and predictive) and discussing the benefits and risks of each. In the real world of complex facility systems, no one maintenance approach is considered optimal or cost effective for any application, system, process, or facility. Rather, each of these has its own unique optimal efficiency point that can be achieved through a combination of all maintenance approaches. A shortened review of the three maintenance approaches is provided below. Greater detail on each of the three approaches is found in the “Maintenance Approaches” (FEMP 2020). The majority of this Best Practice is focused on the fourth approach, RCM.
Reactive Maintenance
Reactive maintenance (also called corrective maintenance) is the “run it until it fails” maintenance approach. In other words, planned maintenance actions (routine, preventive, or predictive) or efforts are no longer taken to assure the equipment’s design life is reached or equipment life is prolonged. Reactive maintenance is almost always unscheduled because it addresses unpredicted failures. The sole function of reactive maintenance is to restore the device or system to a functioning condition after the failure has occurred; this may include device repair or replacement.
The benefits of reactive maintenance can be viewed as a double-edged sword. If you are working with new equipment, you can expect minimal incidents of failure at the beginning of its operating life. If the maintenance program is purely reactive, you will not expend manpower dollars or incur capital costs until something breaks. Because you do not see any associated maintenance costs, you could view this period as one in which money is saved.
Benefits
- Low cost.
- Less staff.
Risks
- Increased cost because of unplanned downtime of equipment.
- Increased labor cost, especially if overtime is needed.
- Cost involved with repair or replacement of equipment.
- Possible secondary equipment or process damage from equipment failure.
- Increased risk of critical-system malfunction or failure.
- Inefficient use of staff resources.
Preventive Maintenance
Preventive maintenance can be defined as follows: Actions performed on a time- or machine-run, time-based schedule that detect, preclude, or mitigate degradation of a component or system to sustain or extend its useful life by controlling degradation to an acceptable level.
While preventive maintenance is typically not the preferred maintenance program, it does have several advantages over that of a purely reactive program. By performing preventive maintenance as the equipment designer envisioned, you will extend the life of the equipment closer to its design life. This translates into monetary savings. Preventive maintenance (lubrication, filter changes, etc.) will generally run the equipment more efficiently, resulting in reduced costs compared to a reactive approach. While this approach will not prevent catastrophic equipment failures, the number of failures will decrease. Minimizing failures translates into maintenance and capital cost savings through reduced downtime and impacts to the facility, its mission, and tenants.
Benefits
- Cost effective in many capital-intensive processes.
- Flexibility allows for the adjustment of maintenance periodicity.
- Increased component life cycle.
- Energy savings.
- Reduced equipment or process failure.
- Estimated 12 to 18 percent cost savings over the reactive maintenance program.
Risks
- Catastrophic failures still likely to occur.
- Labor intensive.
- Includes unneeded maintenance.
- Potential for incidental damage to components while conducting unneeded maintenance.
Predictive Maintenance
Predictive maintenance can be defined as follows: Measurements that detect the onset of system degradation (lower functional state), thereby allowing causal stressors to be eliminated or controlled before any significant deterioration in the component’s physical state. These measurements and their results, as well as the associated analyses, are an indication of current and future system functionality.
Predictive maintenance differs from preventive maintenance by basing the need for maintenance on the actual condition of the machine rather than on a preset schedule. Recall that preventive maintenance is time based. The fundamental difference between predictive and preventive maintenance is that predictive maintenance schedules maintenance tasks based on the quantified condition of the equipment, whereas preventive maintenance schedules tasks solely based on time.
Traditional predictive maintenance technologies include:
- Thermography.
- Oil analysis.
- Ultrasonic analysis.
- Vibration analysis.
- Motor analysis.
- Performance trending and root-cause analysis.
The benefits of predictive maintenance are many. A well-orchestrated predictive maintenance program should all but eliminate catastrophic equipment failures.
Benefits
- Increased component operational life and availability.
- Allows for preemptive corrective actions.
- Decrease in equipment or process downtime.
- Decreased disruptions to mission, tenant activities, or both.
- Decrease in costs for parts and labor.
- Better product quality.
- Improved worker and environmental safety.
- Improved worker morale.
- Energy savings.
- Estimated 8 to 12 percent cost savings over a preventive maintenance program.
Risks
- Increased investment in diagnostic equipment.
- Increased investment in staff (or contracted staff) training.
- Savings potential not readily seen by management.
Reliability-Centered Maintenance
RCM can be defined as a logical, structured process used to determine the optimal failure management strategies for any system based on the system’s reliability characteristics (i.e., the reliability profile) and the intended operating context. RCM defines what must be done for a system to achieve the desired levels of safety, environmental soundness, and operational readiness at the best cost. RCM should be applied continuously throughout the life cycle of any system (DoD 2018).
The history of RCM dates back to the 1960s and the U.S. airline industry’s examination of the relationship between maintenance, reliability, and safety. At the time, the prevailing theories on maintenance asserted that because mechanical parts wear out, the major mode of failure must be age-related. This theory led to the popular component failure profile depicted by the “bathtub curve” (Figure 1) and its three distinct zones of failure potential: Zone 1 – Infant Mortality; Zone 2 – Useful Life; and Zone 3 – Wear Out/End of Life.
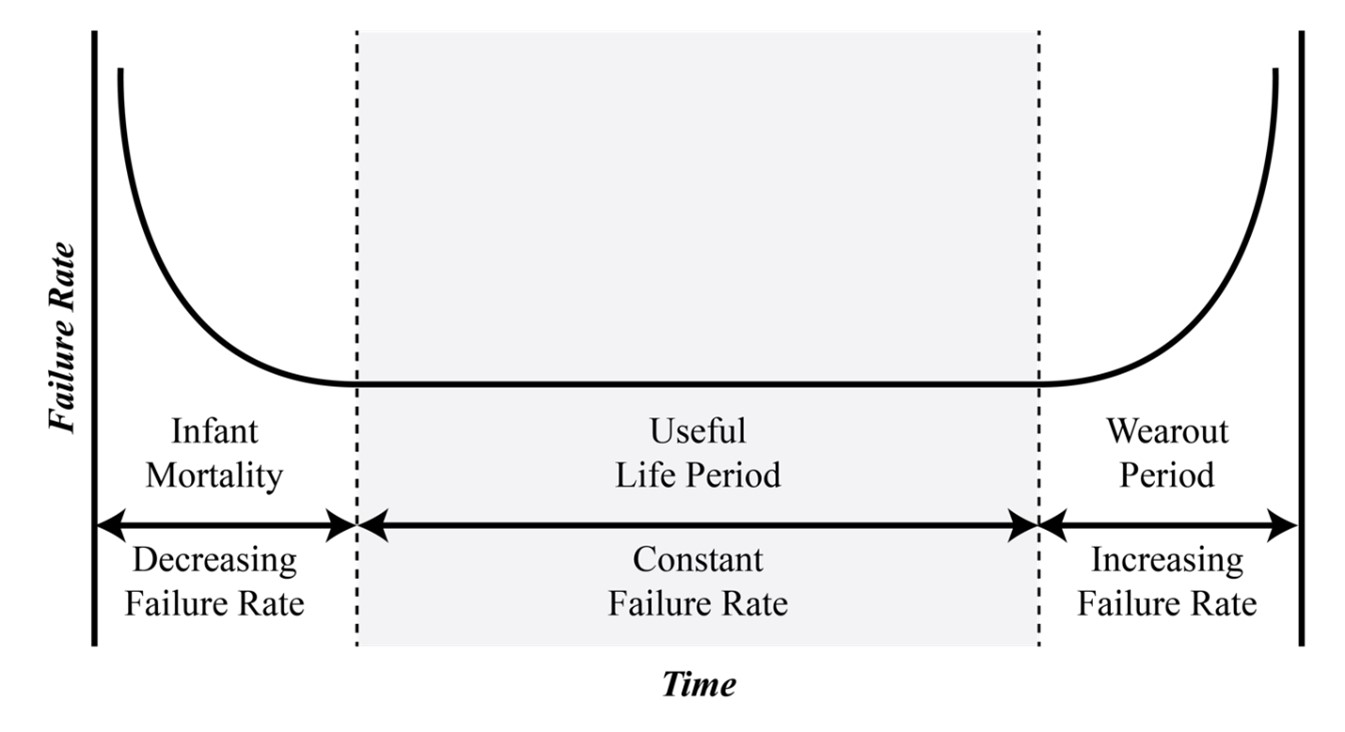
While the bathtub curve is intuitive and useful for describing a traditional component life cycle, age-related studies pioneered by the airline industry and the U.S. Department of Defense (and subsequently the U.S. Navy, the Nuclear Power Industry, and NASA) have shown that age-related failures account for less than 20 percent of all failures. In fact, these studies have shown that random component failures are much more common and account for roughly 80 percent of all failures.
Table 1 presents the results of three case studies conducted in the 1970s and early 1980s. Their outcomes reinforce that most failures are random in nature. As shown in the table, the age-related profiles are I, II, and III. Averaging across these three profiles results in a failure probability of under 20 percent. The random-type failure profiles (profiles IV, V, and VI) tell a different story, with some variance. The average rate of random failure is well above 80 percent. The upshot of this research has highlighted that if a maintenance strategy is based solely on a “fixed time” between maintenance activities and if the majority of equipment fails in a random sense, then the time-based (or age-based) strategy will have limited efficacy.
Using these data and other studies, the maintenance industry began a fundamental shift away from age-based procedures and toward activities focused on component monitoring to predict condition (predictive maintenance). While this transition is clear, so is the reality that predictive maintenance methods are not economically justified for some components or systems—a good example would be a restroom ventilation fan, for which reactive maintenance is acceptable.
From this reality was born the concept of RCM and the need for an optimal failure management strategy that is based on the component, its reliability characteristics, the operating conditions, and the user’s tolerance for risk.
Table 1. Probability Failure Profiles, Rates, and Characteristics
| Profile Type | Failure Profile Shape X-axis = time Y-axis = failure rate | Failure Type Failure Percentages (Nowlan 1978, Broberg 1973, MSDP 1993) | Failure Characteristics |
|---|---|---|---|
I | Failure Type: Age-based Failure Rate: 4%, 3%, 3% | Bathtub curve – typical of mechanical devices with wear-in periods or early generation consumer electronics. | |
II | Failure Type: Age-based Failure Rate: 2%, 1%, 17% | Constant failure probability followed by a pronounced wear-out region. Typical of reciprocating engines. | |
III | Failure Type: Age-based Failure Rate: 5%, 4%, 3% | Gradually increasing failure probability. Typical of turbine engines. Typical of tires or brakes. | |
IV | Failure Type: Random Failure Rate: 7%, 11%, 6% | Low initial failure probability followed by quickly increasing and then constant probability. Typical of high-stress devices. | |
V | Failure Type: Random Failure Rate: 14%, 15%, 42% | Relatively constant probability of failure across all time. Typical of well-designed devices. | |
VI | Failure Type: Random Failure Rate: 68%, 66%, 29% | Infant mortality followed by relatively constant failure probability. Typical of modern electronic devices. |
RCM recognizes that equipment’s design intent and its actual operation can be quite different. RCM approaches the structuring of a maintenance program by recognizing that a facility does not have unlimited financial and personnel resources and that the use of both needs to be prioritized and optimized. In short, RCM is a systematic approach to evaluating a facility’s equipment and resources to best match the two and result in a high degree of facility reliability and cost effectiveness. RCM is highly reliant on predictive maintenance but also recognizes that conducting maintenance activities on low-risk, non-critical, or inexpensive equipment may best be left to a reactive maintenance approach.
Table 2 highlights both industry average maintenance program percentages and those making up top-performing facilities that embrace the RCM concept (FEMP 2010). It should be noted that both programs use all three types of maintenance approaches but differ in how they allocate the reactive and predictive maintenance approaches.
Table 2. Industry Average and Top-Performing Maintenance Approach Percentages
| Maintenance Approach | Industry Average Maintenance Program | Top-Performing Maintenance Program |
|---|---|---|
| Reactive Approach | > 55% | < 10% |
| Preventive Approach | 30%–35% | 25%–35% |
| Predictive Approach | 10%–15% | 45%–55% |
Because RCM is so heavily weighted in its use of predictive maintenance technologies, its program advantages and disadvantages mirror those of predictive maintenance. Beyond these aspects, RCM relies on an analytical approach focused on root-cause analysis, FMEA, or both. Using the RCM approach for facility maintenance allows a site to better match resources to program needs while improving reliability and program economics.
Benefits
- It has the potential to be the most efficient maintenance program.
- Lowers costs by eliminating unnecessary maintenance or overhauls.
- Minimizes the frequency of overhauls.
- Reduces the probability of sudden equipment failures.
- Reduces the impact on critical functions.
- Able to focus maintenance activities on critical components.
- Increases component reliability.
- Incorporates root-cause analysis.
Risks
- It can have significant start-up cost, training, equipment, etc.
- Savings potential not readily seen by management.
- Program benefits have longer horizons and can be difficult to quantify.
Solutions and Actions
RCM Analytics
The analysis steps for an RCM program are defined below (DoD 2011; SAE 1999) and provide specific actions, activities, and capabilities that should be considered before implementation. While an RCM program can function without fully developed capabilities in these functional areas, they are presented as requisites for a fully developed RCM program.
1. Identify asset functions. This step focuses on defining asset functions in the context of the environment as well as necessary performance, code requirements, or both. What is Important in this step is to understand both the asset design function as well as the user function while noting that these can be different things at times. Making certain to define how the asset is actually used and documented is also important.
2. Discover the functional failures. Identify the failure types (i.e., the range of failures that can occur). Examples of this may include:
- A complete failure in which the part or asset no longer performs.
- A partial failure occurs when an asset or part performs but at a reduced output or level.
- A partial failure occurs when an asset or part performs at a reduced, but acceptable (temporary), level.
3. Classify failure causes. The events (or modes) by which assets can fail (i.e., their root causes) are usually well known by the asset or part manufacturer. Whether these events are known or are in need of discovery by root-cause analysis or FMEA, the failure modes can be classified into one of the following:
- Those that have happened before.
- Those that have not happened but have a real or high probability of occurring.
- Those that have not happened but have a low probability of occurring.
- Those that are currently actively managed by a failure management strategy.
4. Identify the effects of failure. Failure effects describe the outcome of each active failure mode. Failure effects should address failures at the local (i.e., component), the assembly (i.e., what the component is attached to or drives), and the system levels. All effects should be identified, including operational, non-operational, safety, and environmental effects.
5. Quantify the effects of failure. Once identified, the effects of failure should be quantified. While this is not always an easy or precise task, it is important to assess the value (economic or otherwise) of a failure in terms of the component, system, or organization. Failure consequences can and are often tracked by benchmarking O&M KPIs or metrics, including:
- Safety, injury, loss of work.
- Environmental compliance or code.
- Maintenance backlogs or equipment downtime.
- Mission, including readiness or resilience.
- Bottom-line economics, budgets, spare parts inventory, etc.
6. Determine optimal maintenance approaches. Using the output of Steps 1–5, Step 6 focuses on identifying the optimal actions that can help predict, detect, identify, and hopefully prevent potential component failures. This step is the essence of effective RCM, whereby information is collected, prioritized, quantified, and acted upon with the goal of creating safe, economic, secure, reliable, and resilient systems.
7. Identify alternatives. The final step encompasses actions that can be taken when a proactive or optimal maintenance approach cannot be found or is not warranted. In some cases, the acceptable alternative is no maintenance at all (restroom fan example) and the component, part, or system is simply replaced upon failure.
Having the capability to complete an RCM analysis, even on a single component, part, or system, is an important first step for the development of a full RCM program.
How to Initiate an RCM Program
As defined, the RCM structure incorporates the maintenance strategies of reactive, preventive, and predictive approaches coupled with proactive maintenance analytics, including root-cause analysis and FMEA. The objective of a functional RCM program is to provide the requisite availability, reliability, and resilience while being based on documented economic and technical justification.
Initiating an RCM program will vary by organization, site, and system type—one RCM program structure does not fit all organizations. Important in the development will be an understanding of how an organization changes and who may be good champions for the design, development, and communication of this program. Also important will be the structure of reporting (what and to whom) at the different levels that exist within the organization.
The framework provided below offers the main components of a functional program; the program weighting and level of activity within any one element will be a local decision. These steps are a culmination of approaches researched through a variety of sources (FEMP 2010, DoD 2011, NASA 2008, and SAE 1999) and are provided as an outline and starting point. Active developers of expanded RCM programs should consult the listed resources as well as others provided at the end of this Best Practice and on the web.
Step 1: Determine Project Scope. The focus of this step is to identify the project scope and objectives of the RCM program, notably:
- Which facilities or systems, if any, will be considered.
- What the defined objectives are (e.g., reliability, efficiency, safety, and resilience).
Before moving to Step 2, it is very important that site management is fully aware, educated, and supportive (both strategically and financially) of this effort. Step 2 begins with a commitment to the process, large or small, for which management support will be critical.
Step 2: Prioritize Project Scope. This step helps organize potential RCM activities by importance or criticality to the operation, process, or mission. Table 3 highlights a system priority weighting for RCM development (PNNL 2010). Those systems having a weighting of 1, 2, or 3 are typically prioritized as holding the greatest RCM potential. The goal here is to assign levels of risk or criticality based on the consequences of failure.
Table 3. System Criticality Priority Matrix for RCM Development
| Weighting | Description | Application |
|---|---|---|
| 1 | Emergency | Life, health, and safety risk – mission critical |
| 2 | Urgent | Continuous operation of facility at risk |
| 3 | Priority | Mission support and/or project deadlines |
| 4 | Routine | Prioritized: first come/first served |
| 5 | Discretionary | Desired but not essential |
| 6 | Deferred | Accomplished only when resources allow |
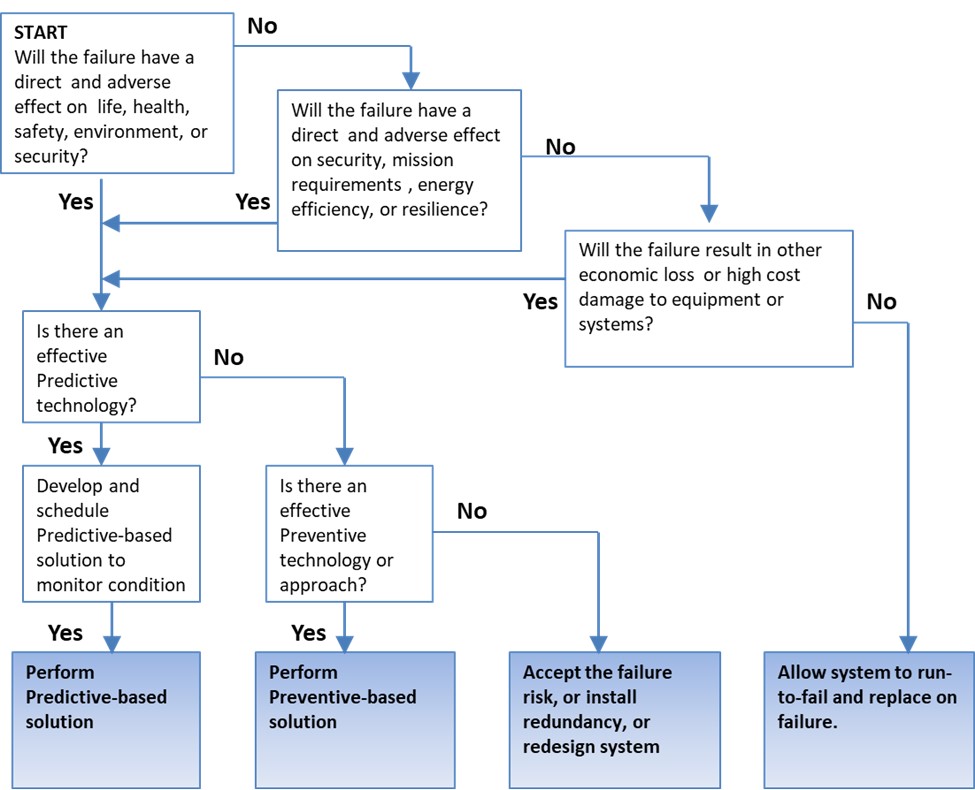
Step 3: Analysis Priorities. Based on the system prioritization and using the RCM analysis methods presented in the previous section, we determine the maintenance approach for each relevant system or component. Figure 2 (derived from NASA 2008) presents a logic tree useful in guiding system- and component-level RCM decision approaches.
Step 4: Staffing/Training Needs. The transition to a functional RCM program will require significant staff training. Training should include an initial focus on RCM principles but have a dedicated focus on the relevant RCM processes and technologies. With proper resources, training can be facilitated by in-house staff or contracted to capable outside organizations.
Step 5: Implementation. Given the potential complexity of an RCM program, implementation should start slowly, and perhaps with a pilot program. Consider starting with a target system that has been challenging from an O&M perspective but also has definable success indicators. Systems that support critical functions and experience downtime could also be good candidates. Choosing a system that has performance indicators (KPIs) that will be compared against benchmarks (industry standards or internally developed) is a well-defined way to measure benefits. At the outset, consider visible systems that have a significant performance history to serve as these baseline KPIs. Applying Key Performance Indicators (FEMP 2020) provides relevant KPIs that will be useful in this step.
Once a system is chosen and an RCM path is implemented, it is important to keep accurate records of all that is happening and not happening. All time and costs related to operation, downtime, equipment purchases, training, contracting, and spare parts inventory need to be tracked. This data will become the basis for determining program benefits.
Step 6: Sustaining the RCM Program. A functional RCM program will be organized, flexible, economic, and visible. The program will have the ability to change with changing systems, programs, and directives. Also important will be the ability to measure and report system benefits in the terms required by decision makers. To accurately track and report progress, RCM metrics can be segregated into three reporting areas: business metrics, program management metrics, and technical metrics (FEMP 2010; DoD 2011).
- Business metrics reflect the cost and benefits of the RCM program for the resource provider, the end user, and the customer. These metrics encompass the direct and indirect costs associated with implementing and sustaining the RCM program. Return on investment, net present value, and life-cycle cost are common business metrics.
- Program metrics focus on the progress and viability of the program. These metrics assess viability by tracking staff numbers, scheduling, systems analyzed, maintenance backlogs, training milestones, and safety records, among others.
- Technical metrics identify the functional aspects of the systems and equipment. These metrics quantify a host of technical performance metrics such as system availability, mean time between failures, types and duration of maintenance performed, and failure rates.
By accurately capturing, analyzing, and reporting program data and benefits, a healthy RCM program will be well on its way to cost justification and resulting in a sustainable, adaptable, and resilient program.
Conclusions and Next Steps
RCM is a holistic and systematic approach to maintenance that is based on cost effectiveness, asset life, safety, and resilience. RCM employs all aspects of the three predominant maintenance approaches—reactive, preventive, and predictive—along with a structured analysis that includes root-cause analysis and FMEA. In general, there is no prescribed path to RCM development. Effective programs start at the system level and prioritize activities by assigning levels of risk based on the consequences of failure, the development of the technical aspects, and proposed cost effectiveness.
Proven paths to successful RCM implementation include starting small and keeping the program manageable before growing. Consideration should be given to a pilot program focused on one or a few systems that are problematic and would benefit from RCM’s detailed approach.
It is important to develop communication pathways to allow buy-in from management and to keep detailed records of cost, performance, and equipment impacts to assess cost effectiveness. The analytic and implementation steps annotated in this Best Practice should be considered as starting points, along with the recommended references, to initiate a successful RCM program.
Case Studies
A. NASA Facility Maintenance. NASA has been immersed in RCM for many years in both its mission-related and facility systems and makes use of two different levels of RCM depending on the system type, risk, and priorities. The first is the rigorous approach (also called the classical approach), which entails detailed system-, subsystem-, and component-level analyses that are typically reserved for high-cost systems such as aircraft and space systems. The second is the intuitive approach (also called the streamlined or abbreviated approach) is often used for facility-type systems and is much more economical to implement. The stated goal that NASA has for facilities is that “facilities and equipment owned by NASA shall be maintained in the most cost-efficient fashion to create a hazard-free working environment while protecting and preserving capital investments and their capability.”
At the outset, NASA’s investment in test equipment, software, training, and additional personnel needed to implement RCM was $15 million over three years. While this investment resulted in increased maintenance activity as faults were detected and corrected and potential failures were addressed, this activity gradually decreased. After RCM development, implementation, and operation, NASA commissioned an economic study of its RCM program, which concluded that the return on investment was 1.75 to 2.2 years (NASA 2008).
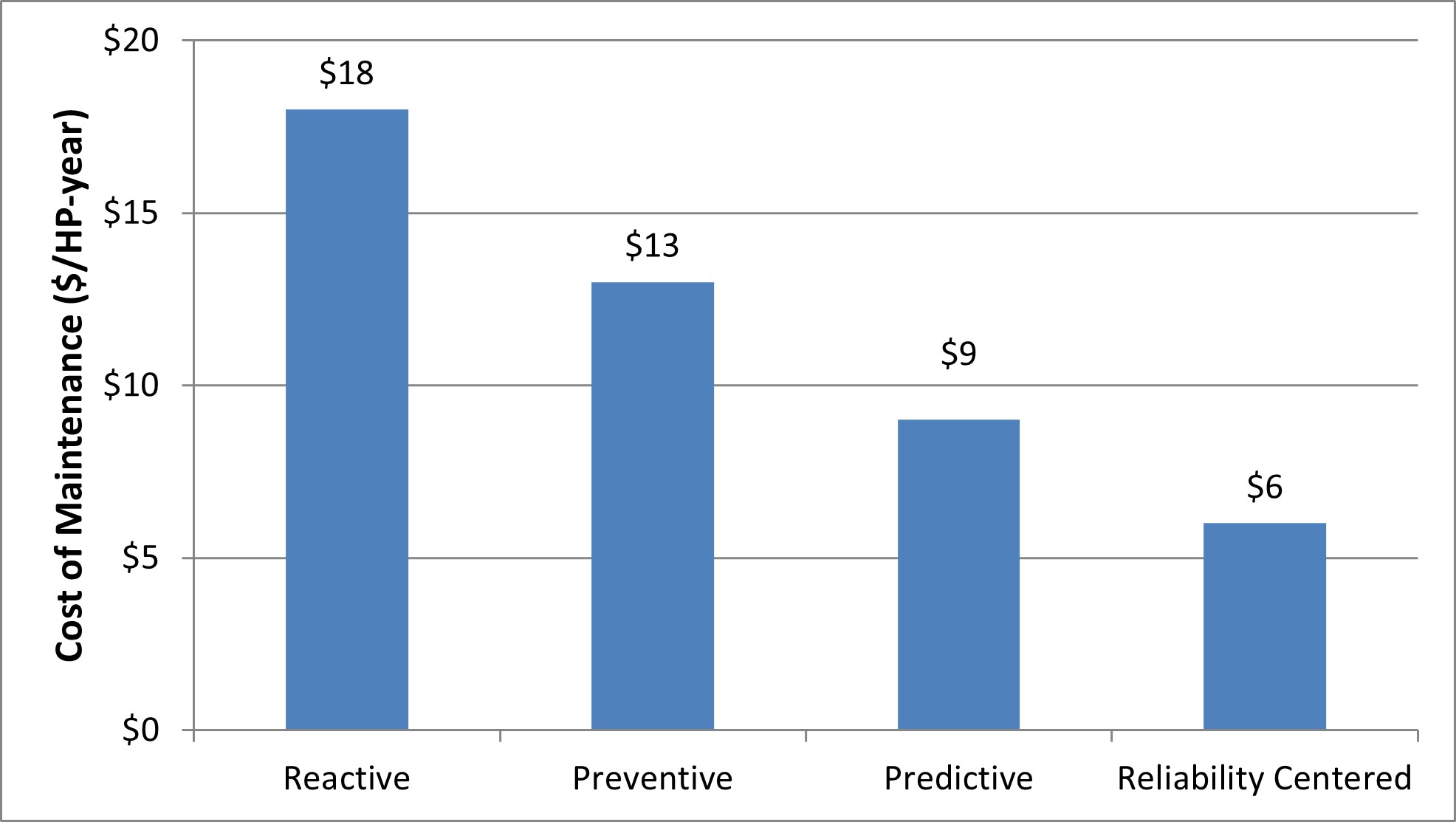
B. Maintenance Cost per Horsepower. The cost of maintenance of the mechanical systems per horsepower can be presented as a function of the horsepower affected. One study referenced these values in annual cost per affected horsepower across the four predominant O&M approaches—reactive, preventive, predictive, and RCM maintenance (FEMP 2010). Figure 3 highlights the average annual maintenance cost differential by maintenance approach. Presented as a function of percentage cost increase over RCM, reactive maintenance represents a 200 percent increase, preventive maintenance a 150 percent increase, and predictive a 50 percent increase.
Additional Resources
FEMP O&M Best Practices Website
FEMP O&M Best Practices have been developed for a variety of topics, such as these, and those listed below have been presented here for their relevancy.
- “O&M Best Practices Issues Discussion: Healthy Building O&M in Existing Buildings”
- “Existing Building Commissioning Approaches”
- “Applying Key Performance Indicators”
- “OMETA: An Integrated Approach to Operations, Maintenance, Engineering, Training, and Administration”
- “Re-tuning Buildings.”
Additional best practices are available at the FEMP O&M Best Practices website.
Whole Building Design Guide
The WBDG is a resource that consolidates the full range of federal building construction and operations design, construction, and operation policies, specifications, and requirements, inclusive of O&M. Development of the WBDG is a collaborative effort among federal agencies, private-sector companies, nonprofit organizations, and educational institutions. Its success depends on industry and government experts contributing their knowledge and experience to better serve the building community. The WBDG offers a number of resources that address RCM. A brief overview of RCM can be found at https://www.wbdg.org/resources/reliability-centered-maintenance-rcm.
References
Broberg, Broberg´s report 1973. Cited in Failure Diagnosis & Performance Monitoring, Vol. 11 edited by LF Pau, published by Marcel-Dekker, 1981.
Department of Defense. 2011. Mil-Std-3034. Department of Defense Standard Practice: Reliability-Centered Maintenance (RCM) Process. U.S. Department of Defense, Washington D.C. http://reliabilityanalytics.com/reliability_engineering_library/MIL-STD-3034_Reliability_Centered_Maintenance_Process_21_Jan_2011/MIL-STD-3034_Reliability_Centered_Maintenance_Process_21_Jan_2011_pp_1.htm
Department of Defense. 2018. Reliability Centered Maintenance. DoD Manual 4151.22-M. U.S. Department of Defense, Washington D.C. https://www.esd.whs.mil/Portals/54/Documents/DD/issuances/dodm/415122m.pdf?ver=2018-10-31-105524-570
FEMP ─ Federal Energy Management Program. 2010. Operations & Maintenance Best Practices: A Guide to Achieving Operational Efficiency. Release 3.0. Prepared by Pacific Northwest National Laboratory for FEMP, Richland, WA. https://www.wbdg.org/FFC/DOE/DOECRIT/femp_omguide.pdf.
MSDP Studies, Age Reliability Analysis Prototype Study, American Management Systems, U.S. Naval Sea Systems Command Surface Warship Directorate, USA, 1993. Cited in Proceedings of the World Congress on Engineering 2015, Volume II, London, U.K. http://www.iaeng.org/publication/WCE2015/WCE2015_pp814-819.pdf
NASA – National Aeronautics and Space Administration. 2008. Reliability Centered Maintenance Guide for Facilities and Collateral Equipment. National Aeronautics and Space Administration, Washington, D.C. https://www.hq.nasa.gov/office/codej/codejx/Assets/Docs/RCMGuideMar2000.pdf
Nowlan FS and HF Heap. 1978. Reliability-Centered Maintenance, Department of Defense, Washington D.C.
SAE 1999. Evaluation Criteria for Reliability-Centered Maintenance (RCM) Processes. Standard JA 1011 199908. Society of Automotive Engineers, Warrendale, PA. https://www.sae.org/standards/content/ja1011_199908/
Published May 2022