RemPlex Summit Technical Sessions

Big Data Analytics, Artificial Intelligence, and Machine Learning for Environmental Remediation of Complex Environmental Systems
Nov. 11, 2021, 10:45 am - 12:15 pm
Organizer(s): Jason (Zhangshuan) Hou, Pacific Northwest National Laboratory (PNNL), Richland, Washington; Haruko Wainwright, Lawrence Berkeley National Laboratory, Berkeley, California; Reed Maxwell, Princeton University, Princeton, New Jersey; Chris Johnson, PNNL
A tremendous amount of environmental remediation data has been collected for waste sites around the world, particularly at heavily studied and high visibility sites like Hanford (USA), Sellafield (UK), and Fukushima (Japan). Such data consists of high dimensional, multiscale, multi-physics data collected for a range of contaminants, times, locations, and data types. The nature and volume of the environmental data provide opportunities and the necessary inputs for developing and applying big data analytics (BDA), artificial intelligence (AI), and machine learning (ML) for remediation of complex environmental systems. We seek research contributions which include, but are not limited to: (1) Development and application of BDA/AI/ML to facilitate understanding and design of multiscale, multi-phase remediation systems; (2) Physics-informed ML and ML-guided numerical modeling to increase the effectiveness and reduce the effort related to the design of remediation and monitoring systems; (3) Reduction of system complexity or identification of influential drivers of remediation system behaviors; (4) Exploratory data analysis, pattern recognition, and signature discovery to provide a better understanding of the remediation and its progress over time; and (5) Acquisition/compilation of environmental data within a remediation engineering context to generate environmental remediation benchmark datasets that are findable, accessible, interoperable, and reusable (FAIR) for ML, providing a basis for remediation decision-making and adaptive and effective remediation design and assessment.
Nov. 11 Technical Session Recording Now Available |
|
|
Speaker #1
Haruko Wainwright
Lawrence Berkeley National Laboratory, Lawrence, California
Advanced Long-term Environmental Monitoring Systems (ALTEMIS) for Sustainable Remediation
Co-authors: Aurelien Meray, Masudur Siddiquee, and Himanshu Upadhyay, Florida International University; Zexuan Xu, Baptiste Dafflon, Sebastian Uhlemann, and Brian Quiter, Lawrence Berkeley National Laboratory; Hansell Gonzalez-Raymat, Miles E Denham, and Carol A Eddy-Dilek, Savannah River National Laboratory
Abstract
Sustainable remediation has emerged as a key concept to address soil and groundwater contamination over the past decade, promoting the transition from intense soil removal and treatments towards more effective and sustainable approaches as well as passive remediation and monitored natural attenuation (MNA). Long-term monitoring is critical for such sites to confirm system stability and the continuing reduction of contaminant and hazard levels, and to detect changes or anomalies in contaminant mobility (if they occur). The Advanced Long-term Environmental Monitoring Systems (ALTEMIS) project funded by the Department of Energy, Office of Environmental Management aims to establish the new paradigm of long-term monitoring based on state-of-art technologies – in situ groundwater sensors, geophysics, drone/satellite-based remote sensing, reactive transport modeling, and AI – that will improve effectiveness and robustness, while reducing the overall cost. In particular, we focus on (1) spatially integrative technologies for monitoring system vulnerabilities – surface cap systems and groundwater/surface water interfaces using geophysics, UAV and distributed sensors, and (2) in situ in-well sensor technologies for monitoring master variables that control or are associated with contaminant plume mobility and direction, (3) open-source machine learning framework, PyLEnM (Python for Long-term Environmental Monitoring) for spatiotemporal interpolations and monitoring design optimization, and (4) high-performance computing-based contaminant transport modeling for evaluating monitoring designs and climate vulnerability/resilience. This system transforms the monitoring paradigm from reactive monitoring – respond after plume anomalies are detected – to proactive monitoring – detect the changes associated with the plume mobility before concentration anomalies occur. In addition, through the open-source package, we aim to improve the transparency of data analytics at contaminated sites, empowering concerned citizens as well as improving public relationship.
Speaker #2
Aurelien Meray
Florida International University, University Park, Florida
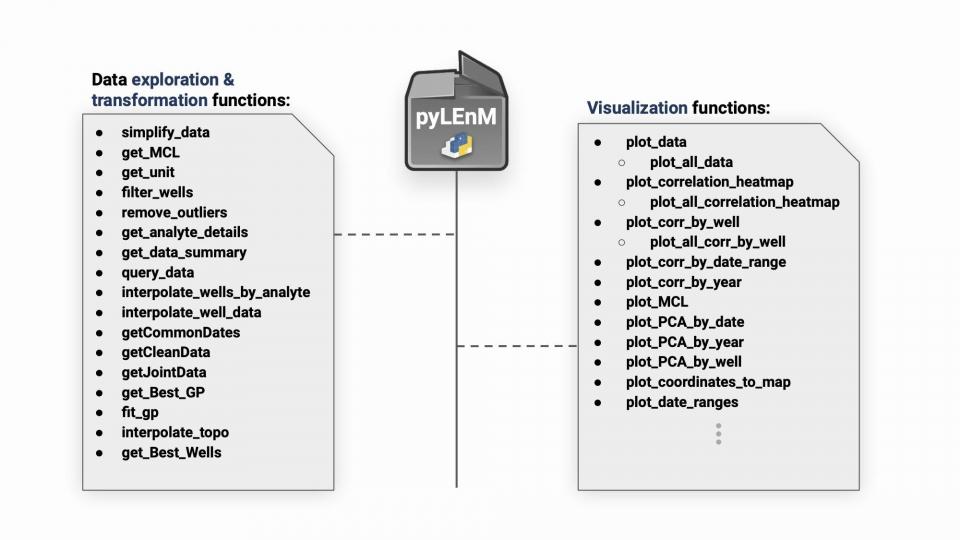
pyLEnM: A Python based Machine Learning Framework for Long-term Water Quality Monitoring and Remediation
Co-authors: Masudur R. Siddiquee, Himanshu Upadhyay, and Leonel E. Lagos, Florida International University; Haruko Wainwright, Lawrence Berkeley National Laboratory
Abstract
Technological progress in the areas of geophysics, in-situ groundwater sensors, satellite-based remote sensing, reactive transport modeling, and artificial intelligence (AI) have all increased the efficacy and reliability of long-term monitoring systems for contaminated groundwater sites. In situ sensors have proven to be a strong alternative to traditional groundwater sampling and laboratory analysis, especially when it comes to monitoring master variables, which are frequently leading indicators of plume movement change. Despite these advances, there are still issues to be solved, such as where to install additional sensors, determine which in situ variables provide the most information, and how to successfully anticipate plume movement using contaminant concentration estimations. The research described herein involves the development of a suite of machine learning algorithms in the form of an open-source python package to facilitate the analysis of monitoring datasets effectively. Particular focus was on extracting critical information from a historical dataset, by analyzing multiple time series of groundwater contamination data and groundwater quality parameters such as pH, water table, and specific conductance. The algorithms developed analyze and visualize the correlations between different analytes and help identify key parameters that control contaminant concentrations and plume movement. Additional focus was put on the development of an advanced spatial interpolation algorithm that uses a combination of regression and kriging techniques to accurately estimate contaminant plumes. Lastly, a sensor placement algorithm, which is built on top of the spatial interpolation method, was created to effectively select locations from a set of existing wells to maximize the capture of critical information for predictive modeling for new sensors.
Speaker #3
Masudur Siddiquee
Florida International University, University Park, Florida
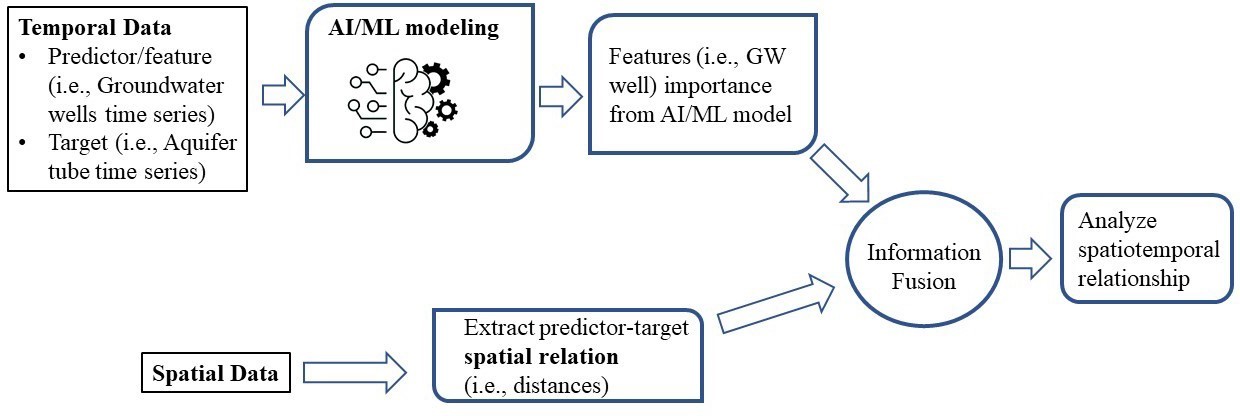
Artificial Intelligence Based Spatiotemporal Relationship Exploration
Co-authors: Aurelien Meray, Santosh Joshi, Himanshu Upadhyay, and Leonel Lagos, Florida International University; Vicky L. Freedman and Rob D. Mackley, PNNL
Abstract
In a contaminated nuclear site, a lot of variables affect the contaminant concentrations in the groundwater temporally as well as spatially. For instance, water table, river stage, and active cleanup efforts. Although cleanup efforts planning includes as much of these variables as possible in consideration, sometimes cleanup targets are not achieved in some parts of the cleanup zone due to complex hydrogeological processes and interactions among various water sources. In such a situation, probable spatiotemporal relationship exploration may help to actuate the cleanup efforts to achieve the goal and optimize monitoring resources. In this research, a method was developed for spatiotemporal relationship exploration using the legacy dataset of groundwater monitoring data leveraging Artificial Intelligence/Machine learning (AI/ML). In this method, AI/ML modeling was used to extract the relational information from the time-series data, for instance, feature importance of the time series as a predictor in the AI/ML model. In machine learning, feature importance refers to a score assigned to an input feature based on how useful that feature was in predicting the target variable. From the various sources of the feature importance, decision tree-based importance calculation was chosen for the current AI/ML modeling approach. Specifically, a Random Forest ensemble algorithm was used which constructs many individual decision trees at the training phase. Each of those decision trees is a set of internal nodes and leaves where the features are selected based on some criteria, such as Gini impurity or information gain in classification task and mean squared error (MSE) reduction in regression task. For each feature, the average of the metric of selection criterion can be collected from the decision trees. Then the average over all the trees in the RF model would be the measure of the feature importance score for the features or predictor time series. In the spatial part of the method, distances between the predictors and target variable in the AI/ML was used as a metric. For the information fusion of this spatial metric to the temporal features from the AI/ML model, regression analysis was used as an example. This method led to a decreasing trend in the spatial features to the temporal features for a publicly available representative soil and groundwater contaminant dataset.
Speaker #4
Elliot Chang
Lawrence Livermore National Laboratory, Livermore, California
Speciation Updated Random Forest Modeling as a Hybrid Machine Learning Approach to Predict Radionuclide-Mineral Sorption
Co-authors: Haruko Wainwright, University of California-Berkeley; Mavrik Zavarin, Lawrence Livermore National Laboratory
Abstract
Historically, reactive transport models have provided important simulation results on the mobility and fate of radionuclides in subsurface geologic systems. The effectiveness of these models hinge in part on surface complexation models (SCMs) that provide geochemically informed sorption-based retardation information. While our SCM reaction workflow using the recently developed Lawrence Livermore National Laboratory Surface Complexation/Ion Exchange (L-SCIE) database reasonably predicts uranium-quartz sorption for a large number of literature-mined data (n=526, R2 = 0.88-0.94, depending on the choice of SCM construct), a hybrid machine learning (ML) approach has shown promise in improving predictions (R2 = 0.92-0.98). At its core, the random forest ML approach presented in this study is motivated by a successful effort in digitizing raw sorption community data contained in the RES3T database. Our new hybrid ML model presented herein incorporates important geochemical information through aqueous speciation calculations while also implementing a data-driven random forest decision making process to determine mineral sorption phenomena. Named the LLNL Speciation Updated Random Forest (L-SURF) model, this study provides evidence for successful application of a high performing new hybrid approach to simulate radionuclide-mineral interactions, as will be demonstrated for the test case of uranium-montmorillonite sorption (R2 = 0.93-0.98) in this presentation.

Speaker #5
Xueyuan Kang
Nanjing University, Nanjing, Jiangsu, China
Integration of Deep Learning-based Inversion and Upscaled Mass-transfer Model for DNAPL Mass-discharge Prediction and Uncertainty Assessment
Co-authors: Amalia Kokkinaki, University of San Francisco; Xiaoqing Shi and Jichun Wu, Nanjing University; Hongkyu Yoon, Sandia National Laboratories; Jonghyun Lee, University of Hawaii at Manoa; Peter K. Kitanidis, Stanford University
Abstract
The challenges posed by detailed characterization of dense nonaqueous phase liquid (DNAPL) 3D source zone architecture (SZA) have motivated the development of simpler, upscaled models that rely on domain-averaged characterization metrics to capture the average response downstream of a DNAPL source zone (SZ). However, the highly irregular SZA makes estimating these domain-averaged metrics from sparse borehole data extremely difficult. With a poor estimation of SZ metrics, the upscaled models may fail to reproduce the complex, multistage effluent concentrations. To improve the characterization of SZ metrics and better predict multistage concentrations while maintaining computationally efficiency with the upscaled models, we develop a multiphysics-constrained deep learning-based 3D SZA inversion method (i.e., CVAE-ESMDA, Convolutional Variational Auto-Encoder – Ensemble Smoother with Multiple Data Assimilation). We then integrated the CVAE-ESMDA method with the process-based (PB) upscaled mass-transfer model for effluent concentration prediction. We evaluated our method (i.e., CVAE-ESMDA-PB) with data from two real-world 3D flowcell experiments of Zhang et al. (2008), with significantly different SZAs and multistage effluent concentrations. The results show that the CVAE-ESMDA can capture the main features of the reference SZA and satisfactorily characterize the SZ metrics, with some loss in fine-scale features. Based on the estimated SZ metrics, the PB model can reproduce the essential features of the mass-discharge profiles but underestimates the magnitude of effluent concentrations. The proposed method can also quantify well the effluent-concentration prediction uncertainty that stems from the estimation error in SZ metrics (i.e., source zone projected area, the average of local-scale DNAPL saturations and effective permeability).
SNL is managed and operated by NTESS under DOE NNSA contract DE-NA0003525.
Speaker #6
Jason (Zhangshuan) Hou
PNNL
Machine Learning Applications for Studying Hydrobiogeochemistry in the Columbia River Basin
Abstract
The nature and volume of the environmental system characterization, monitoring, and simulation data provide opportunities and necessary inputs for developing and applying big data analytics (BDA), artificial intelligence (AI), and machine learning (ML) for understanding and remediation of complex environmental systems, for example, the Hanford Remediation Site, its pump and treat systems, the Hanford Reach river corridor system, and the downstream dams or floodplains. This presentation will discuss some research progress, opportunities, and challenges in applying AI and ML approaches for studying hydrobiogeochemical processes along the Columbia River in the pacific northwest of US. These include AI/ML-based mechanistic understanding of environmental system behaviors, reduced order models, predictive models, data augmentation, as well as AI/ML-assisted parameter/factor ranking and guidance on experimental design. Challenges related to model transferability and data inadequacy/imbalance issues will be discussed.