ddKS
Comparing samples of high dimensional data is a challenging task with relevance to many fields including climate modeling, high energy physics, and machine learning. The ddKS package computes the differences between two high dimensional distributions quickly using our accelerated, “d-dimensional Kolmogorov-Smirnov distance”.
POC: Alex Hagen
CODE | PAPER
MCL
Minos Computing Library, or ‘MCL’, is a modern task-based, asynchronous programming model and runtime for executing complex scientific workflows on extremely heterogeneous systems.
CODE | Paper

TAZeR
Transparent Asynchronous Zero-Copy Remote I/O, or ‘TAZeR’, is a remote I/O framework that reduces effective data access latency in large scale scientific workflows.
POC: Ryan Friese
CODE | Paper

Lamellar
Lamellar is an asynchronous tasking and PGAS runtime for HPC systems developed in RUST.
POC: Ryan Friese
CODE
SODA-Opt
SODA-Opt is a tool that enables identifying segments of applications written in high-level productive programming frameworks (Python, Machine Learning) for hardware acceleration through high-level synthesis tools. SODA-OPT is developed within the MLIR compiler infrastructure.
POC: Antonino Tumeo
CODE | Paper

OpenCGRA
OpenCGRA is an open-source unified framework for modeling, testing, and evaluating specialized Coarse-Grained Reconfigurable Arrays (CGRAs).
POC: Antonino Tumeo
CODE | Paper
Svelto
Svelto is a high-level synthesis methodology for the automated generation of high-throughput accelerators for graph analytics and irregular computation.
POC: Antonino Tumeo
CODE | Paper
HLS of Task Parallel Specification
HLS of Task Parallel Specification is a High-Level Synthesis methodology that generates specialized accelerators starting from high-level parallel programs. The methodology combines together statically scheduled accelerators in a dataflow architecture.
POC: Antonino Tumeo
CODE | Paper
BigFlowSim
BigFlowSim is a workflow I/O simulator-emulator and trace generator that captures several parameters that affect local and remote I/O performance. BigFlowSim generates a large variety of flows within and between tasks of distributed workflows. With BigFlowSim, we have systematically studied TAZeR's performance on different data flows.
POC: Ryan Friese
CODE | Paper
PALM
Palm is a suite of performance modeling tools (Palm, Palm-Task, Representative-Paths, Palm/FastFootprints, MIAMI-NW) to assist performance analysis and predictive model generation. Palm generates models by combining top-down (human-provided) semantic insight with bottom-up static and dynamic analysis. Palm has been used to model irregular applications with sparse data structures and unpredictable access patterns. Recent additions focus on rapid characterization of memory behavior.
POC: Nathan Tallent
CODE | Paper

STM
STM is a temporal motif-based tool for graph characterization and embedding generation.
POC: Sumit Purohit
CODE | Paper
QLiG
QLiG is a Graph-based Query specification to construct structural, approximate queries for Property Graph using high-level concepts such as path, structure, and constraints.
POC: Sumit Purohit
CODE | Paper
GridPack
GridPack is a power grid simulation framework that is designed to simplify the development of power grid simulations that can run on a range of machines, from desktop workstation to high performance computing platforms. GridPACK is written in C++ and consists of a collection of libraries and software modules that can be used to build power grid applications that can run on advanced architectures. In addition, it has many complete application modules that can be used either standalone, to run standard simulation or can be combined in new ways to create more complicated simulation workflows.
POC: Bruce Palmer
CODE | PAPER

TranSEC
TranSEC is a scalable approach to estimating vehicle travel times at the street level using aggregated Uber data and graph representations of the underlying road network. Approach demonstrated for LA and Seattle metro area networks.
POC: Arun Sathanur, Arif Khan

TransBEAM
TransBEAM is a set of classes and methods to analyze and compare different state-of-the-art data-driven building energy modeling techniques. The module also implements transfer learning to make use of both the simulation data and sparse field data.
POC: Milan Jain, Arun Sathanur
CODE
Qual2M
Quantitative Learned Latency Model, or ‘Qual2M’, is the implementation of a Machine Learning methodology for quantitative performance of optimized latency-sensitive code on CPUs. To capture the cost distribution and the most severe bottlenecks, Qual2M combines classification and regression using ensemble decision trees, which also provide some interpretability.
POC: Arun Sathanur, Nathan Tallent
CODE
NWQ-Sim
NWQ-Sim is a quantum system simulation environment running on classical heterogeneous supercomputers. It currently comprises a state-vector simulator (SV-Sim) and a density-matrix simulator. It supports Intel/AMD/IBM CPUs, NVIDIA/AMD GPUs, Xeon Phi, etc. as the backends, and Q#/Qiskit/OpenQASM as the frontends. NWQ-Sim has been deployed on OLCF Summit, ALCF Theta and NERSC Perlmutter, scaling-out to more than a thousand of CPUs or GPUs. NWQ-Sim is currently used for noisy simulation of quantum chemistry, optimization, linear algebra, and communication applications. NWQ-Sim is supported by the U.S. Department of Energy, Office of Science, National Quantum Information Science Research Centers, Quantum Science Center (QSC).
POC: Ang Li
NWQ-Sim CODE | SV-SIM cODE | dm-sIM cODE | qir-aLLIANCE cODE | pAPER 1 | pAPER 2
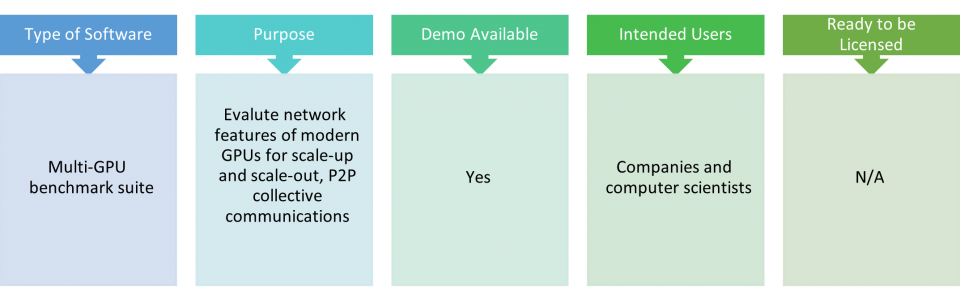
Tartan
Tartan is a multi-GPU benchmark suite used for evaluating modern GPU interconnect, such as NVLink, NVSwitch, PCIe, etc. It has three categories: a microbenchmark for measuring interconnect latency, throughput, communication efficiency, NUMA effect, etc. for both peer-to-peer and collective communications; a scale-up benchmark with seven applications for intra-node (i.e., single-node-multi-GPUs) evaluation; and a scale-out benchmark with seven applications for inter-node (i.e., multi-nodes) evaluation. Tartan was supported by U.S. DOE Office of Science, Office of Advanced Scientific Computing Research, under award 66150: "CENATE - Center for Advanced Architecture Evaluation".
POC: Ang Li
CODE | Paper 1 | Paper 2
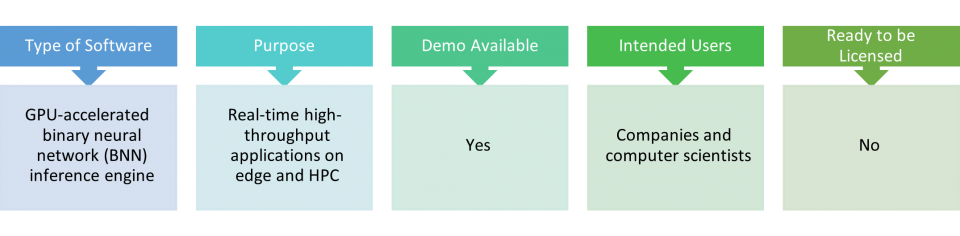
SBNN
SBNN is a GPU-accelerated high-performance inference engine for binarized neural network. It has two version: “BSTC” that runs on GPU CUDA cores leveraging GPU’s native bit instructions for ultra-low-latency BNN inference, achieving 1000X single-image (from ImageNet) inference latency reduction over TensorFlow; “TCBNN” that runs on Turing and Ampere GPU tensor-cores, achieving high throughput. SBNN was supported by the DS-HPC project under PNNL’s Deep-Science LDRD Initiative.
POC: Ang Li
CODE | Paper 1 | Paper 2
ARENA
ARENA is an architecture and runtime prototype for the next generation reconfigurable HPC. ARENA is a non-von-Neumann architecture adopting an asynchronous, locality-driven, task-based execution model for reconfigurable platforms. ARENA brings computation to the data rather than the reverse, significantly reducing (unnecessary) data-movement and boost execution performance. ARENA has been demonstrated on multi-FPGA and multi-CGRA platforms. The ARENA runtime and architecture design is supported by the Compute-Flow-Architecture (CFA) project under PNNL’s Data-Model-Convergence (DMC) LDRD Initiative.
POC: Ang Li
CODE | Paper