Data-driven scientific discovery drives the need for converged applications that integrate scalable science applications with machine learning (AI/ML) infrastructure to enhance modeling and simulation capabilities. As such, converged scientific applications are complicated and require coordination of several components. Proxy application driven software-hardware co-design plays a vital role in driving innovation among the developments of applications, software infrastructure and hardware architecture. Proxy applications are self-contained and simplified codes that are intended to model the performance-critical computations within applications. While there is disagreement in the HPC community on the mechanisms of construction of the proxy applications, there is a strong consensus on their positive impact in co-design. The need for achieving sustainable strong scalability on future extreme-scale heterogeneous systems drives the considerations for designing appropriate proxy applications and abstractions.
The goals of the AMAIS MLS thrust are to 1) develop/utilize high-level distributed-memory programming abstractions for rapid prototyping of data-intensive machine learning applications, 2) devise efficient heuristics and methods to optimize data movement for application scenarios (especially sparse and irregular applications that are memory-access driven) considering latest advances in high-capacity standards-based memory infrastructure, and 3) perform quantitative evaluation to assess systems performance at different scales.
The scope of this research thrust can be divided into three main categories: machine learning prototyping, graph and sparse analytics, and workload characterization and analysis.
Machine Learning Prototyping
In this area, we consider different AI/ML use cases, spanning from custom models used in lab projects to foundational and general model architectures such as RESNET. We investigate standalone and minimally dependent implementations which can be used to build diverse deep learning architectures for co-design. We have been studying optimization techniques to improve memory consumption and model size (of classification problems), possible via unsupervised feature reduction in the context of classical machine learning approaches.
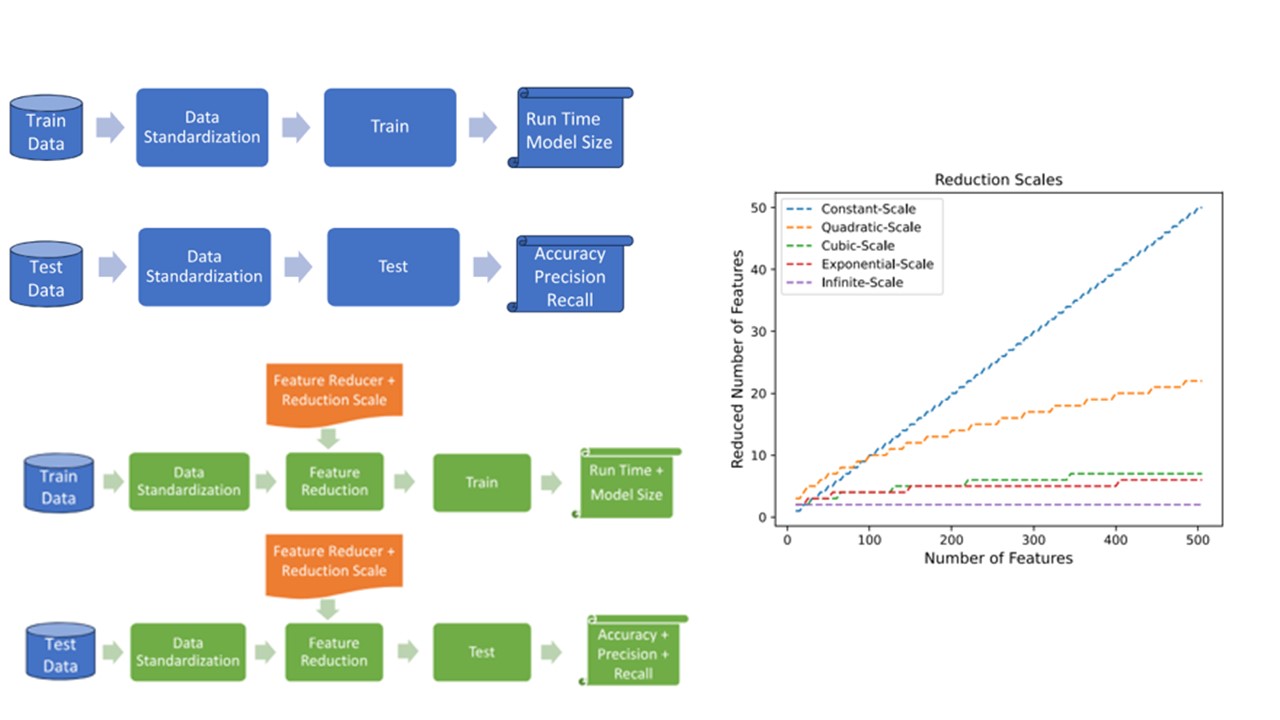
Paper:
Subasi O, Ghosh S, Manzano J, Palmer B, Marquez A. Analysis and Benchmarking of feature reduction for classification under computational constraints. Machine Learning: Science and Technology. 2024 Mar 22.
Graph and Sparse Analytics
Graphs are ubiquitous in modeling complex systems and representing interactions between entities to uncover structural information of the domain. Traditional graph analytics aims to solve unsupervised problems to learn from unlabeled data at scale, while graph-aware machine learning plays a key role in node classification and link prediction problems. Graph and sparse analytics scenarios exhibit high and irregular memory accesses, and often suffers from the limited memory bandwidth on contemporary architectures. We investigate low-level memory access and communication adaptations to improve bandwidth of graph applications, via data structures to enhance frequent memory lookups, communication strategies to improve bandwidth and architecture-specific optimizations.
Several sparse matrix operations such as Sparse Matrix-Sparse Matrix GEMM (SpGEMM) and Sparse Matrix-Dense Matrix (SpMM) are frequently used in AI/ML training and inference scenarios since sparsity is endemic in deep learning. We are working towards supporting key sparse matrix operators over distributed memory high-level interfaces, to cater to massive graph processing at scale.
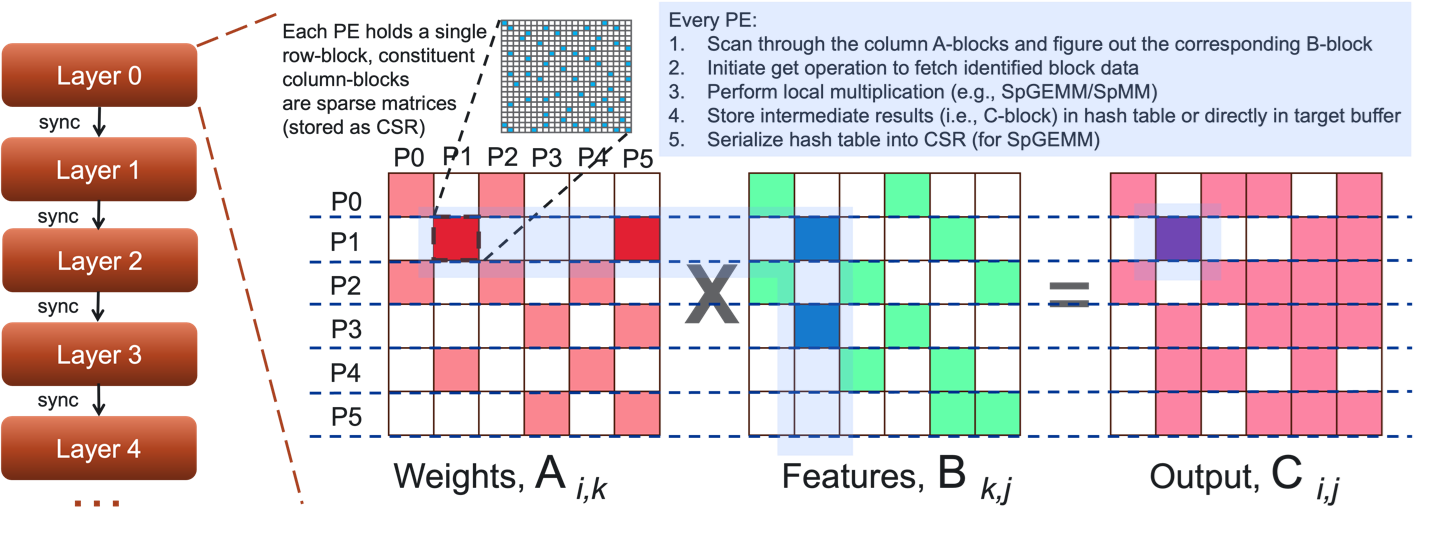
Papers:
Lee H, Jain M, Ghosh S. Sparse Deep Neural Network Inference Using Different Programming Models. In 2022 IEEE High Performance Extreme Computing Conference (HPEC) 2022 Sep 19 (pp. 1-6). IEEE.
Ghosh S. Improved Distributed-memory Triangle Counting by Exploiting the Graph Structure. In 2022 IEEE High Performance Extreme Computing Conference (HPEC) 2022 Sep 19 (pp. 1-6). IEEE.
Kang Y, Ghosh S, Kandemir M, Marquez A. Impact of Write-Allocate Elimination on Fujitsu A64FX. In Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region Workshops 2024 Jan 11 (pp. 24-35).
Workload Characterization and Analysis
Machine Learning applications exhibit a wide variety of diverse workloads depending on the model and underlying framework/runtime. We study prototypical codes using third-party ML framework (e.g., building models with neural network layers and functions, Physics-informed ML, etc.) on contemporary accelerator-enabled systems and perform detailed profiling to understand the source of performance issues. We are organizing a database that depicts performance profiles of a range of ML application scenarios that can be used to analyze bottlenecks (e.g., low device occupancy, unbalanced FLOPs/byte, etc.) on current platforms and can be leveraged to co-design specialized accelerators.
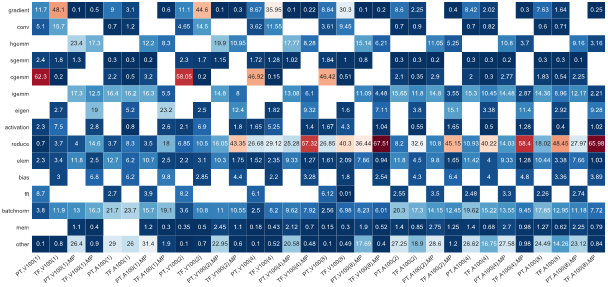
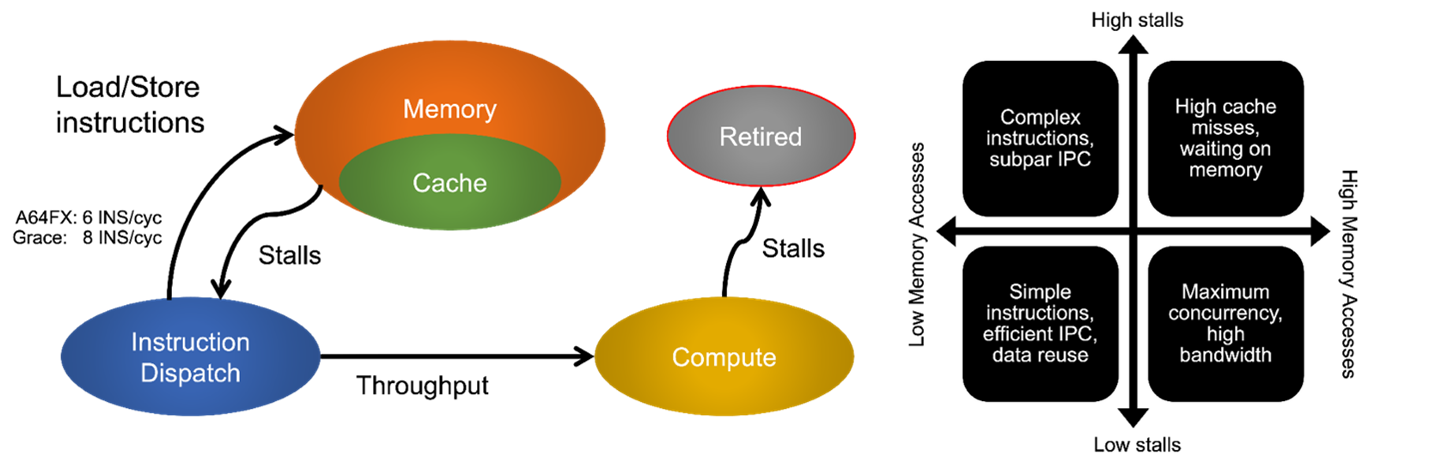
Papers:
Jain M, Ghosh S, Nandanoori SP. Workload characterization of a time-series prediction system for spatio-temporal data. In Proceedings of the 19th ACM International Conference on Computing Frontiers 2022 May 17 (pp. 159-168).
Kang Y, Ghosh S, Kandemir M, Marquez A. Impact of Write-Allocate Elimination on Fujitsu A64FX. In Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region Workshops 2024 Jan 11 (pp. 24-35).
Kang Y, Ghosh S, Kandemir M, Marquez A. Studying CPU and memory utilization of applications on Fujitsu A64FX and Nvidia Grace Superchip. In 10th International Symposium on Memory Systems (MEMSYS 2024).