The Software Defined Architectures (SODA) Synthesizer is a fully open-source toolchain that enables generating the design of highly specialized hardware accelerators starting from specifications in high-level productive programming framework, focusing on Machine Learning Frameworks such as PyTorch, TensorFlow, and TFLite. SODA is composed of a front-end (SODA-OPT), based on the multiLevel Intermediate Representation (MLIR) framework, that performs hardware/software partitioning of the initial specifications and hardware synthesis-oriented optimizations, and of PandA-Bambu, a state-of-the-art high-level synthesis tool, which generates the hardware description language (typically Verilog) representing the domain-specific accelerators. The SODA Synthesizer can then interface with field programmable array (FPGA) or application-specific integrated circuit (ASIC) logic synthesis tool to generate the final design.
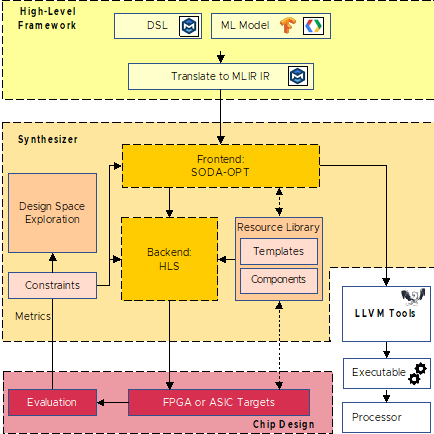
We are leveraging and extending the SODA Synthesizer in several ways for the AMAIS project. The SODA Synthesizer provides an excellent framework to generate highly specialized near memory accelerators targeted at artificial intelligence. We are modifying the synthesizer so that generated accelerators could directly integrate on prototyping and production near memory engines for memory expansion card. As accessing memory and moving data from memory to accelerators is a critical element for machine learning accelerators that must operate with Terabytes of input data and soon trillions of parameters, we are improving the tools to generate highly specialized memory interfaces and to leverage novel mechanisms for inter-accelerator communication exploiting the CXL protocol. The design and parameters of these interfaces are determined with compile time analysis by the synthesis toolchain and specialized for the generated accelerators.
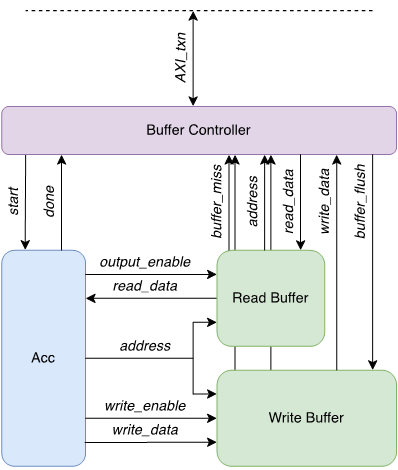
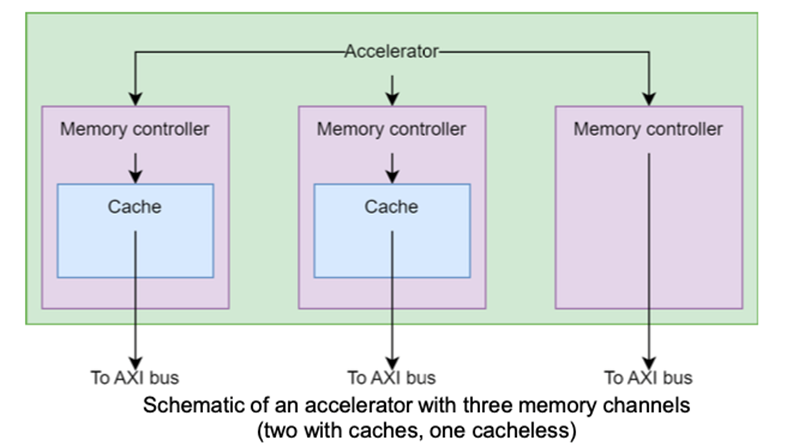
To improve performance with streaming data, we are also designing novel synthesis methodologies that can generate a coarse-grained data-flow architecture, were each dataflow unit can implement operators or layers of an artificial neural network without requiring external controllers to orchestrate the computation and data movement. Connected with the new memory interfaces, this highly specialized design allows to maintain dataflow rate for large machine learning models, minimizing training time and inference latency.
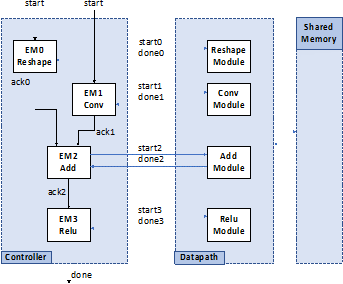
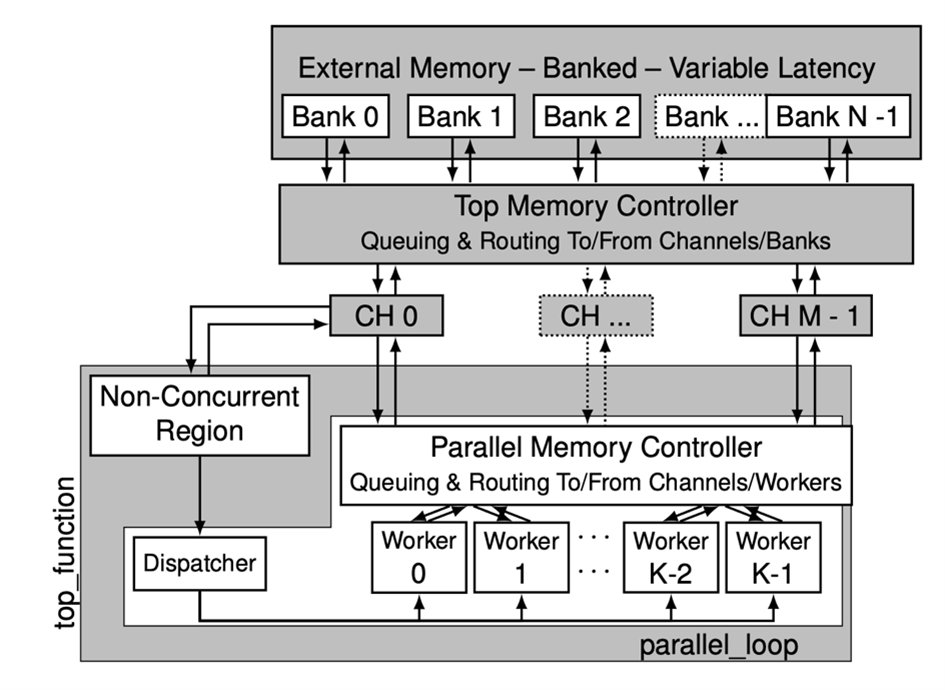
We are also developing advanced synthesis methodologies for parallel multithreaded accelerators starting from parallel shared memory high-level code specifications. These methodologies allow to generate parallel spatial and temporal architectures, to tolerate latency when accessing external memory (dynamic random-access memory, DRAM, or non-volatile memory) with different access times or located at different distances. Coupled with an advanced memory interfacing subsystem and interconnect, support for fine grained synchronization and interfacing with the CXL protocol, these designs allow generating efficient and scalable near memory accelerators for parallel irregular codes without requiring any hardware expertise.
Links:
SODA-OPT: https://github.com/pnnl/soda-opt
PandA-Bambu: https://github.com/ferrandi/PandA-bambu
SODA-Docker: https://hub.docker.com/r/agostini01/soda
SODA Synthesizer Website: https://hpc.pnl.gov/SODA/
Related publications
Ankur Limaye, Nicolas Bohm Agostini, Claudio Barone, Vito Giovanni Castellana, Michele Fiorito, Fabrizio Ferrandi, Andres Marquez, Antonino Tumeo. A Synthesis Methodology for Intelligent Memory Interfaces in Accelerator Systems. Accepted at ASPDAC 2025
Claudio Barone, Rishika Kushwah, Ankur Limaye, Vito Giovanni Castellana, Giovanni Gozzi. Michele Fiorito, Fabrizio Ferrandi, Antonino Tumeo. To Cache or not to Cache? Exploring the Design Space of Tunable, HLS-generated Accelerators. MEMSYS 2024
Ankur Limaye, Nicolas Bohm Agostini, Claudio Barone, Vito Giovanni Castellana, Michele Fiorito, Fabrizio Ferrandi, Andres Marquez, Antonino Tumeo: A Synthesis Methodology for Intelligent Memory Interfaces in Accelerator Systems. DAC 2024 Work-in-progress poster
Claudio Barone, Ankur Limaye, Vito Giovanni Castellana, Giovanni Gozzi, Michele Fiorito, and Fabrizio Ferrandi. Improving Memory Interfacing in HLS-Generated Accelerators with Custom Caches. SC2023 Best Research Poster Candidate
Nicolas Bohm Agostini, Serena Curzel, Jeff Jun Zhang, Ankur Limaye, Cheng Tan, Vinay Amatya, Marco Minutoli, Vito Giovanni Castellana, Joseph B. Manzano, David Brooks, Gu-Yeon Wei, Antonino Tumeo: Bridging Python to Silicon: The SODA Toolchain. IEEE Micro 42(5): 78-88 (2022). Best paper for 2022.
Marco Minutoli, Vito Giovanni Castellana, Nicola Saporetti, Stefano Devecchi, Marco Lattuada, Pietro Fezzardi, Antonino Tumeo, Fabrizio Ferrandi: Svelto: High-Level Synthesis of Multi-Threaded Accelerators for Graph Analytics. IEEE Trans. Computers 71(3): 520-533 (2022)
Serena Curzel, Nicolas Bohm Agostini, Vito Giovanni Castellana, Marco Minutoli, Ankur Limaye, Joseph B. Manzano, Jeff Zhang, David Brooks, Gu-Yeon Wei, Fabrizio Ferrandi, Antonino Tumeo: End-to-End Synthesis of Dynamically Controlled Machine Learning Accelerators. IEEE Trans. Computers 71(12): 3074-3087 (2022)