Objective
- The predictions of deep learning models can be grounded in scientific domain concepts.
- We exploit this understanding to design better methods to locate potential model failures and then revise our models for new information or data.
- To do this, we have two high-level approaches:
- Check for existence of domain concepts, then rewrite a small subset of weights to causally verify.
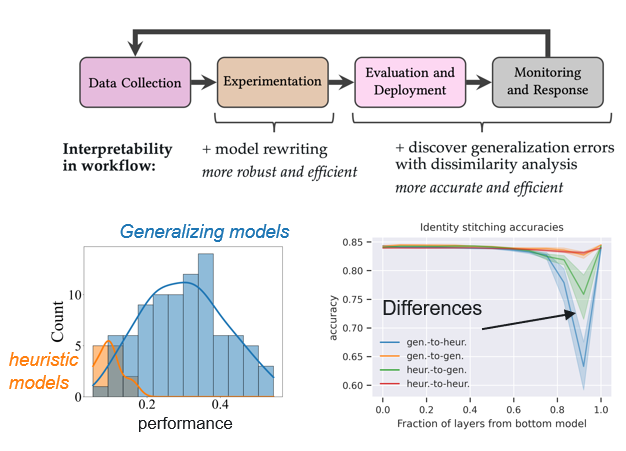
- Compare the hidden layer of understanding of 2+ models with dissimilarity methods, and then identify sources of differences in both the model and the data.
Overview
Successfully deploying deep learning models in uncertain, real-world environments requires models that can be efficiently and reliably modified to adapt to unexpected issues. For this reason, there is growing interest in model editing with domain concepts, which enables computationally inexpensive, interpretable, post-hoc model modifications. AIwC aims to improve our scientific and mathematical understanding of concepts in neural networks and to develop interpretable interventions on neural networks applied to various domains. This project leverages empirical examinations of deep learning models to better connect the theory of deep learning with practice and has developed interpretable and robust model editing algorithms, allowing deep learning models to be more easily understood and rewritten.

AIwC is motivated by recent deep learning interpretability methods that examine and quantify the use of human concepts in deep learning models, including concept activation vectors and the more rigorous attempts to use them. High-level concepts are in part appealing because they can be more easily understood than the pixel-level or image-level outputs used in other explainability methods. They can also be defined at different levels of abstraction, from low-level image statistics like color or spatial frequency to high-level domain concepts like material and structure.
Existing investigations into the usefulness of different components of editing methods are so elaborate that it is unclear which of their moving parts is most responsible for editing success. Now, AIwC team members have developed new model editing algorithms that are more interpretable, robust, and efficient.
Impact
With our methods, we can:
- Discover and locate generalization failures in deep learning models with orders-of-magnitude less data (and 100 to 1000× less data curation effort). Previous approaches less efficient could not locate the hidden layer differences between failing and performing models.
- Robustly fix, or rewrite, deep learning models with orders-of-magnitude less data (and 10 to 100× less training time required). Previous methods (like MEMIT/ROME) are significantly less robust to small distribution shifts.
Publications and Presentations
- Davis Brown, Charles Godfrey, Nicholas Konz, Jonathan Tu, and Henry Kvinge. 2023. Understanding the Inner workings of Language Models Through Representation Dissimilarity. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6543–6558, Singapore. Association for Computational Linguistics.
- Konz N.C., C.W. Godfrey, M.R. Shapiro, J.H. Tu, H.J. Kvinge, and D.R. Brown. 2023. "Attributing Learned Concepts in Neural Networks to Training Data." In Proceedings of the 37th Conference on Neural Information Processing Systems, December 10-16, 2023, New Orleans, LA.
- Godfrey C.W., D.R. Brown, T.H. Emerson, and H.J. Kvinge. 2022. "On the Symmetries of Deep Learning Models and their Internal Representations." In Thirty-fifth Conference on Neural Information Processing Systems.