A model or code is the mathematical representation of a process, device, or concept (Sippl and Sippl 1980) coded into a computer language for execution on a computer, which is consistent with the current preconceived notions of what a model is intended to represent.
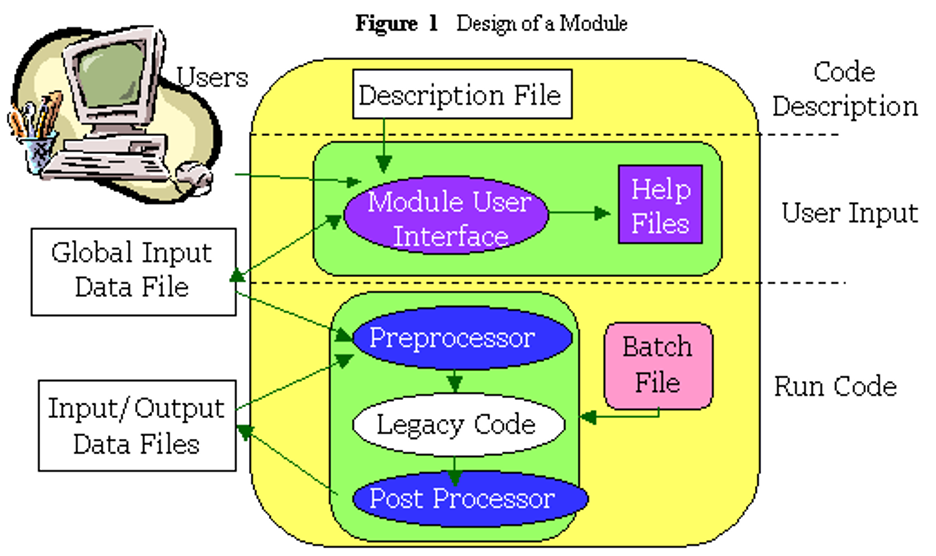
A module consists of a model description, a Module User Interface (i.e., input), and the execution code (i.e., run model), which contains pre- and post-processors for converting the models' input/output for recognition by the model/system. Figure 1 illustrates these three basic components of a module.
The code description describes what the model is, whom you should contact for questions, what information it consumes and produces, the connection schemes with other models that it allows, how the model fits into the system and how it should be perceived by the system.
Figure 1 shows that the Module User Interface, input files, and the executable are separate from each other. By separating these, any Module User Interface associated with a legacy code can remain unchanged, so the user will see no change from the expectations developed when they used the original code outside of the framework. The input may come from the user, which is traditionally associated with the Module User Interface, database(s), and upstream models supplying boundary conditions. By distinctly separating the input from the executable, the sensitivity/uncertainty analyses on the input data is possible. As such, batch files can be established for multiple runs. Finally, the execution code is represented by the legacy code and its pre- and post-processors. The pre-processor converts the input data that the system recognizes into a format that the model recognizes, while the post-processor converts the model output into the standardized system format.