
Advanced Computing, Mathematics and Data
Research Highlights
April 2011
Fewer Faults for Faster Computing
A scalable fault tolerance model for high-performance computational chemistry
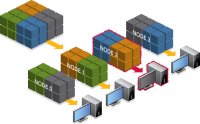
The redundant data distribution of an array showing that a node failure will leave at least one copy of the data available for continued execution. This is the basic idea that enables the approach, which can be used in many science domains. Enlarge Image
{kind=link}
Results: Computational chemistry challenges are now being addressed with a new efficient fault-tolerant method. Researchers at Pacific Northwest National Laboratory have designed and implemented an efficient fault-tolerant version of the coupled-cluster method—a numerical technique for describing many-body systems such as atoms and molecules—for high-performance computational chemistry using in-memory data redundancy. Their method, demonstrated with NWChem, addresses the computational chemistry challenges of reduced mean time between failures, which is currently days and projected to be hours for upcoming extreme-scale supercomputers. These results have been published in the Journal of Chemical Theory and Computation and Association for Computing Machinery Tech News.
Why it matters: The infrastructure the team developed is shown to add an overhead of less than 10% to the amount of time the computational process requires. It can be deployed to other algorithms throughout NWChem, as well as other codes. Such advances in supercomputing will enhance scientific capability to address global challenges such as climate change and energy solutions using top-end computing platforms.
Methods: The team extended the Global Arrays toolkit, a library that provides an efficient and portable "shared-memory" programming interface for distributed-memory computers. Each process in a Multiple Instruction/Multiple Data parallel program can asynchronously access logical blocks of physically distributed dense multidimensional arrays, without requiring cooperation by other processes. Their approach, with coupled-cluster datasets called perturbative triples, enables the program to correctly continue execution despite the loss of processes.
What's next: PNNL researchers will be handling soft errors, which are a major impediment to utilizing the potential of upcoming high-end systems because it can be difficult to detect whether it is simply the data that is wrong, or whether it indicates a design defect or broken component in the system.
Acknowledgment: This work was supported by the eXtreme Scale Computing Initiative at Pacific Northwest National Laboratory.
Research Team: Abhinav Vishnu, Huub van Dam, and Bert de Jong of PNNL.
Reference: van Dam HJJ, A Vishnu, and WA de Jong. 2011. "Designing a Scalable Fault Tolerance Model for High-Performance Computational Chemistry: A Case Study with Coupled Cluster Perturbative Triples." Journal of Chemical Theory and Computation 7: 66-75. DOI:10.1021/ct100439u.