
Advanced Computing, Mathematics and Data
Research Highlights
December 2008
Making Supercomputers More Nimble
Collaborators help large computing systems handle crashing processors
On a computer that could cover a basketball court or two, a calculation that takes days to perform can grind to a halt when a component, such as a processor, memory model, or a hard drive, fails. While a desktop computer usually has no more than a hundred components, a supercomputer can have millions. So, scientists at Pacific Northwest National Laboratory are leading a 3-year project with Ohio State University and Oak Ridge National Laboratory to address the problem of failed components without the need of restarting computations.
Why It Matters: Finding proteins that signal the early onset of breast cancer and other challenges often means solving large intricate calculations that require supercomputers. When a hardware failure is encountered on a supercomputer, the calculation is interrupted and then re-done after repairs are made. With time on these computers often being limited and expensive, faults can delay getting critical answers.
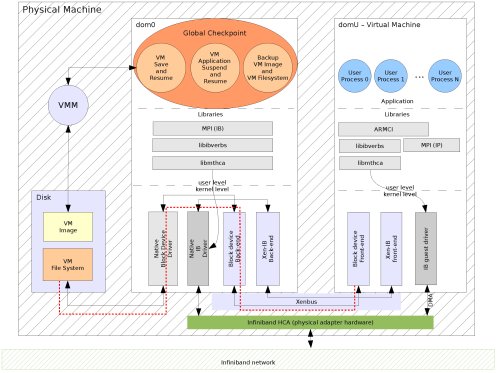
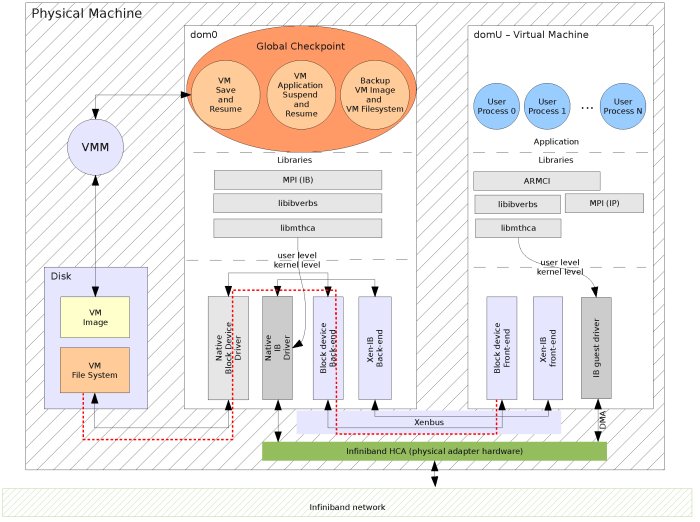
Researchers at Pacific Northwest National Laboratory, Ohio State University, and Oak Ridge National Laboratory are working using approaches, such as the one outlined above, to make supercomputers more tolerant when one or more of its hundreds of processors fail. Enlarged View
{kind=link}
Methods: To make supercomputers nimbly work around faults, the team is taking a two-pronged approach. The first method relies on a technology called virtualization. This technology creates an abstract boundary between the computer hardware and software running on the machine. Thanks to virtualization, periodic checkpoints of the state of the operating system and programs are performed while the calculation is running. In the event of a failure, the calculation is restarted from the most recent backup by adding extra processors to avoid those that failed, and thus losing only hours of time, not days. This approach does not require any change to the application software run on the supercomputers.
In the second approach, the work is divided into tasks with all the processes co-operatively executing them. Each processor, in addition to working on the tasks, stores the results obtained. As the tasks are done, the system tracks the results stored in each processor. In the event of a failure, which causes the loss of computed results, the system quickly determines the tasks that produced the results, and re-executes them.
Of course, working around the failures requires co-ordination, meaning the processor that took over the work of the failed one is now out of sync with the rest of the processors. As an analogy, imagine 20 chefs baking cakes. If the mixer of one chef breaks, that person will be behind the others while the mixer is being replaced. The software assesses the amount of work remaining and re-distributes the tasks to hasten the recovery.
What's Next? The team plans to test these two approaches to fault tolerance on Chinook, the new supercomputer at DOE's EMSL, a national scientific user facility at PNNL.
Acknowledgments: DOE's Office of Advanced Scientific Computing Research funded this work. This work supports PNNL's mission to strengthen U.S. scientific foundations for innovation by developing transformational tools, techniques, and facilities, including those for advanced modeling and computation, for the biological, chemical, environmental, and physical sciences via DOE's EMSL and other user facilities.
References: Scarpazza DP, P Mullaney, O Villa, F Petrini, V Tipparaju, DML Brown Jr, and J Nieplocha. 2007. "Transparent System-level Migration of PGAS Applications using Xen on Infiniband." In Proceedings IEEE Cluster 2007, pp 74-83. Austin, Texas.
Tipparaju V, M Krishnan, F Petrini, J Nieplocha, and BJ Palmer. 2007. "Towards Fault Resilient Global Arrays." In Parallel Computing: Architectures, Algorithms and Applications Proceedings, pp. 347-354, Amsterdam, The Netherlands.
Petrini F, J Nieplocha, and V Tipparaju. 2006. "SFT: Scalable Fault Tolerance." ACM SIGOPS Operating Systems Review 40(2):55-62.